| Faster R | 您所在的位置:网站首页 › faster rcnn模型可用于 › Faster R |
Faster R
|
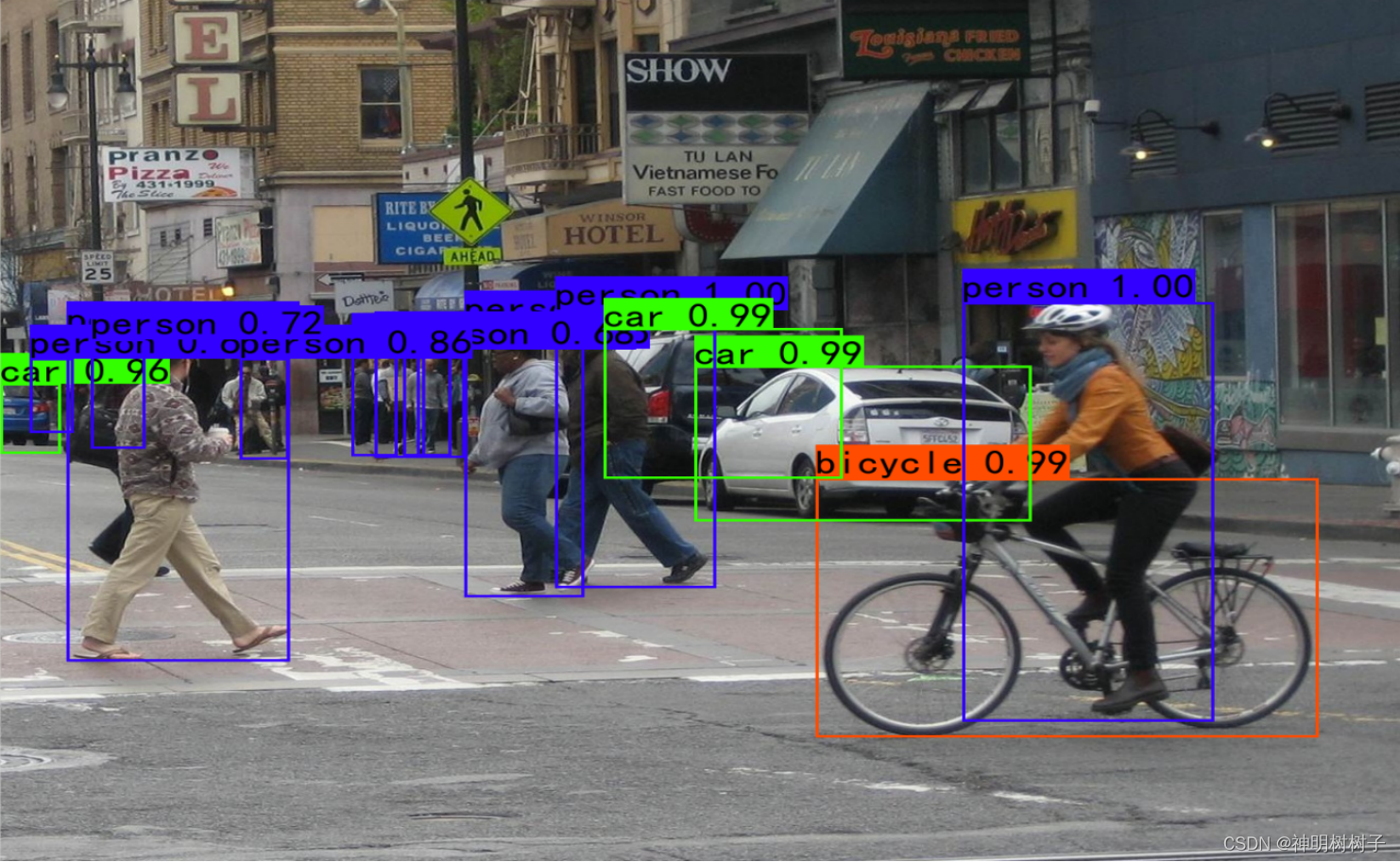
目录 1 前沿 2 两个目标检测模型的比较 2.1 具体例子分析 2.2 模型相同点与不同点 2.3 两模型性能分析 3 结论 1 前沿本文主要对两个模型进行比较,总结其相同点和不同点。 两模型原理及代码见上篇博客: Faster RCNN目标检测模型原理及代码-CSDN博客 基于注意力机制的目标检测模型(DETR模型)原理及代码实现-CSDN博客 2 两个目标检测模型的比较 2.1 具体例子分析对于同一幅图,Faster RCNN 模型预测效果图如下:
DETR模型的预测效果图如下: 利用 frcnn.detect_image(image, crop = crop, count = True)函数将预测的类别与个数在终端打印出来,两个模型在训练的epoch相同的情况下,Faster-RCNN结果显示如图21。同理,DETR模型的预测结果显示如图22。
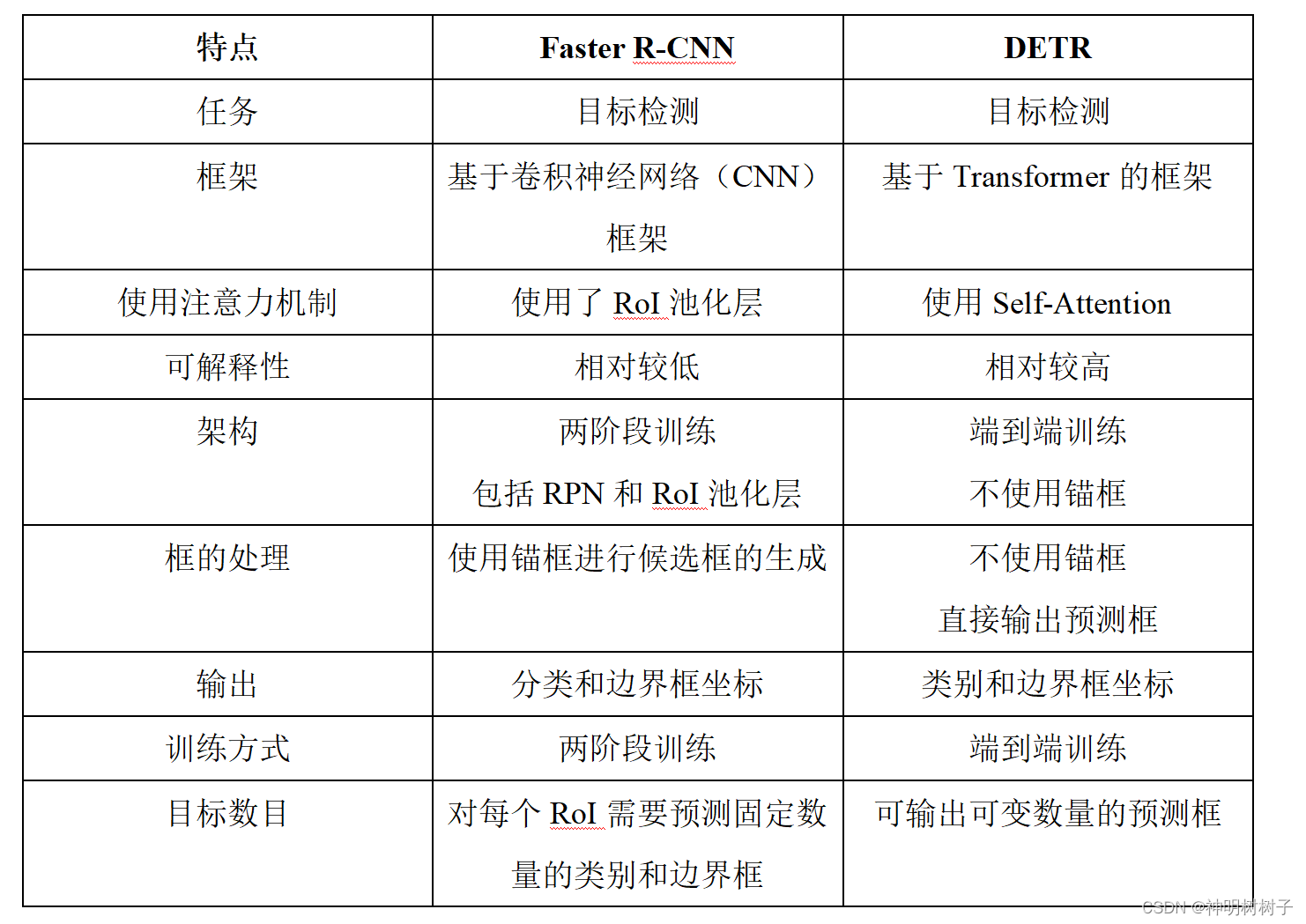
根据如上结果可知,在相同的训练轮数下,检测同一幅图。 从检测到的目标个数来看,DETR模型的效果更好,能识别出的目标更多,例如该模型能识别出car类有3个,person有11个,而相对于Faster-RCNN模型来说能识别出的car只有2个,person只有9个,可能原因是目标缺失不完整导致的。 2.2 模型相同点与不同点下表是两个模型的相同点与不同点。
Faster R-CNN采用了一种两阶段的训练策略,指目标检测模型的训练过程分为两个主要阶段。采用两阶段训练的优势在于,它将目标检测任务分解为两个独立的阶段,使得模型更容易收敛和训练。RPN的引入帮助模型生成高质量的目标区域提议,使第二阶段的目标检测模型能够关注在这些候选区域上进行更准确的分类和边界框回归。 DETR采用了一种端到端训练的策略。端到端训练是指整个目标检测模型的训练过程是一个连续的、端到端的流程,而不需要明确分阶段进行。在传统的目标检测模型中,通常有两个主要阶段:目标区域提议和目标检测。这两个阶段通常分别训练,而DETR采用了一种更简化和统一的方式。下面是DETR端到端训练的关键点: ①不使用锚框。②输出固定数量的预测框。③一次性优化。DETR的端到端训练意味着整个模型(包括注意力机制和目标框的输出)是在单个损失函数的基础上进行优化的。这个损失函数同时涵盖了分类、边界框回归以及目标框位置的匹配等方面。 2.3 两模型性能分析Faster R-CNN模型在VOC数据集上表现出色,其在目标检测精度和速度方面都取得了令人满意的结果。通过两阶段的训练,该模型能够准确地生成目标区域提议,然后进行目标分类和边界框回归。然而,由于两阶段设计,相较于DETR,Fasterrcnn的整体复杂度和计算成本较高。 DETR模型在VOC数据集上展现了其在端到端目标检测任务上的独特优势。通过直接输出一组固定数量的预测框,DETR简化了传统目标检测流程,使得训练和推理更加高效。其在目标检测任务上的性能与传统模型相媲美,同时具有更直接的输出形式。 3 结论本次项目通过对Faster R-CNN和DETR在VOC数据集上的实验对比,我们得出以下结论:Fasterrcnn在传统目标检测任务中表现出色,适用于对准确性要求较高的应用场景。DETR通过端到端训练,直接输出目标框,简化了模型结构,提高了训练和推理效率,特别适用于需要高效处理大量目标的场景。 在选择模型时,应根据任务需求和计算资源来权衡准确性和效率。综合而言,Fasterrcnn和DETR都是强大的目标检测模型,可以根据具体应用场景的要求选择合适的模型。随着目标检测领域的不断发展,更多关于模型结构和训练策略的改进将进一步推动目标检测技术的发展。 |


【本文地址】